Why had we switched from NFS and started to store data separately in each node?
In 2016, one of our customers needed to install InvariMatch in a cluster of several machines. The API and web interface were installed on only one machine, but processing involved all the machines in the cluster. The system worked well after installation, but in early 2017 we detected a problem.
At first, we stored the uploaded video and video added to a search index (registration video) as separate files in several folders. Nodes involved in video processing accessed files via Network File System (NFS). The registration video clips were in a low resolution and allowed us to verify the match accuracy.
With the number of videos in the database rapidly increasing, the InvariMatch work speed began to fall. The speed had dropped significantly more than we expected by April 2017, and we began to research what was going on.
We measured the performance in different parts of the operating system and found out that about 200 thousand files had been accumulated in the folders. Each time a file in the folder was accessed, the NFS had to re-read the list of files, which took about 1 second each time. Not only that, it doubled the network traffic. First, the video uploaded to the server, and then it was transferred via NFS to the nodes where it was processed. The failure of a machine with NFS could lead to the failure of the entire cluster. Moreover, using NFS, we had to synchronize the nodes launch after turning the system on and off. If the nodes were launched earlier than the whole system, it was necessary to wait for the turning on of the main machine with the NFS server.
So we decided to abandon NFS and distribute the files which were being processed to the local nodes. We changed the code and the web interface in the file storage and access system.
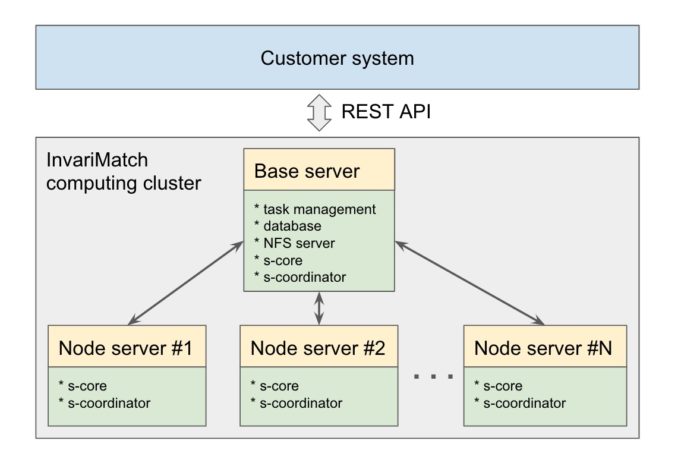
The development was completed in June 2017, and we began testing the system on local machines. Our efforts paid off. The network traffic decreased significantly, individual cluster nodes became more autonomous, and delays while accessing files disappeared. Also, there was no need to use large data storage devices.
We had launched updates on the client’s server at the end of August 2017. As a result, the InvariMatch system became more optimized and reliable.