Почему мы отказались от NFS и перешли на раздельное хранение данных в кластере
В 2016 году для одного из наших клиентов потребовалась установка InvariMatch в кластере из нескольких машин. API и web интерфейс были установлены только на одной машине. Обработкой занимались все машины в кластере. Сразу после установки всё работало хорошо, но в начале 2017 года мы обнаружили проблему.
Дело в том, что работа с видео — это работа с большим объемом информации. Входящее видео и видео, добавленное в поисковый индекс, (регистрационные ролики) хранились в виде отдельных файлов на нашем сервере в нескольких папках. Узлы, участвующие в обработке и сканировании видео, получали доступ к файлам с помощью NFS. Регистрационные ролики из базы данных были в низком разрешении, что позволяло нам проверять корректность совпадений.
В начале 2017 года, когда InvariMatch вышла на промышленную нагрузку, количество видео в базе данных выросло, и скорость её работы начала постепенно падать. В апреле 2017 года, когда скорость упала больше нормы, мы начали выяснять, что происходит.
После замеров времени в разных частях операционной системы оказалось, что в папках скопилось порядка 200 тысяч файлов. Каждый раз при обращении к файлу в этой папке NFS перечитывал список файлов, что занимало значительное время. Кроме того, получался двойной трафик — сначала видео загружалось на сервер, а потом через NFS происходила передача фильма на узел, в котором уже велась обработка. Архитектура системы получалась ненадежной, так как выход из строя машины с NFS приводил к сбою в работе всего кластера. С NFS также приходилось заниматься синхронизацией запуска узлов после включения и выключения системы — если узлы запускались раньше, то им приходилось ждать включения главной машины с NFS сервером.
После обсуждения решили полностью отказаться от NFS и распределить обрабатываемые файлы по локальным узлам. Для этого пришлось сильно изменить систему хранения и доступа к файлам в коде и в web interface.
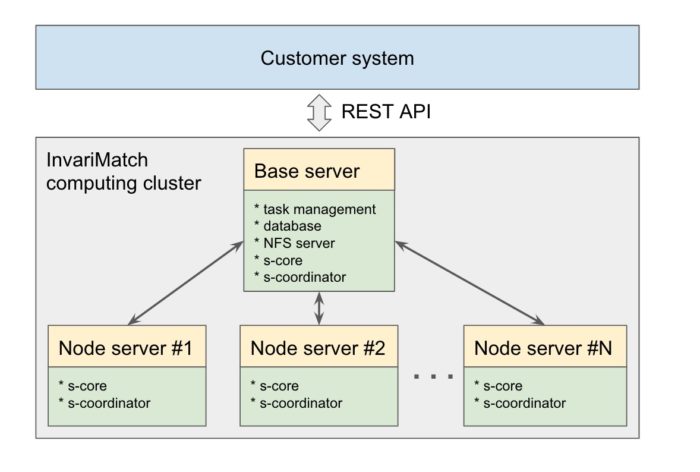
В июне 2017 года разработка алгоритма была завершена, мы начали тестировать его работу на локальных машинах. Результат окупил приложенные усилия — трафик в сети значительно уменьшился, увеличилась автономность отдельных узлов кластера, исчезли задержки при доступе к файлам. Кроме того, отпала необходимость использовать накопители данных больших размеров.
После завершения всех тестов и корректировок мы подготовили план обновления и в конце августа 2017 года запустили обновления на сервере клиента. Так мы оптимизировали работу нашей системы для распознавания и поиска видео и сделали её более надежной и удобной в использовании.